基于Fiddler Selenium Requests的万用爬虫技术
发布时间:2021-12-03
公开文章
背景
上一期文章爬取了微信文章的阅读数和点赞数,于是,接着很早之前的想法,尝试实现换头输的万用爬虫技术。
Fiddler Selenium用于测试,本主在若干年前,遇到过JS动态加密网页文本的Web,最终祭出大杀器Selenium搞定,缺陷就是速度慢。而且,因为Selenium只能自动提供Cookies,不能给出完整的headers,所以,没有将三者结合起来使用。现在,可以通过换请求头,实现当年github F**k-login的功能,具体实现如下:
技术实现
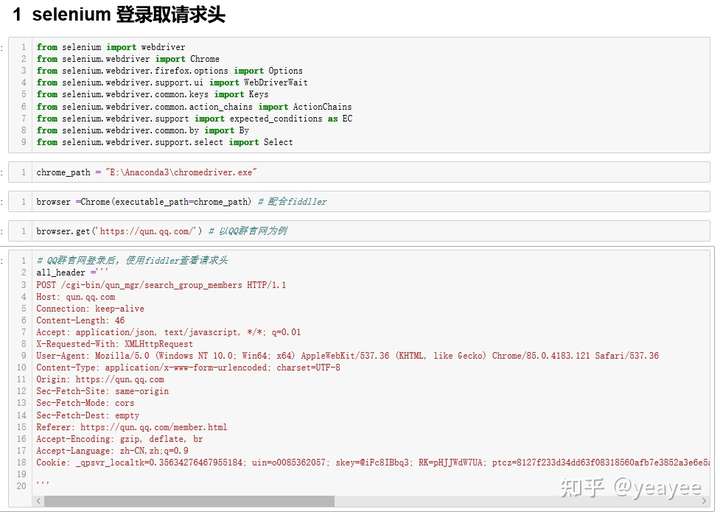
为了保证请求状态延续性,使用selenium进行手动登录QQ群官网;有些网站,在退出当前浏览器,就会更新cookies,退出登录状态。然后使用Filler再次获取目标网址的请求参数,重新构造Get\Post请求:
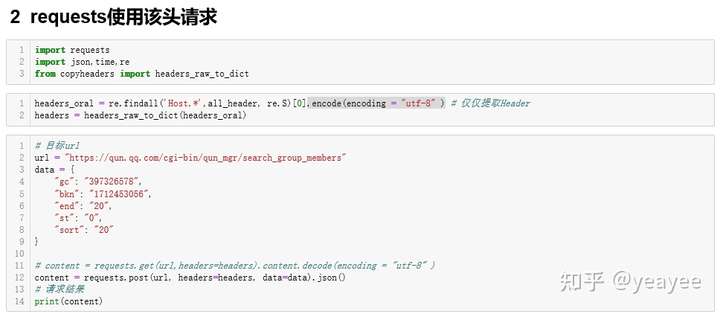
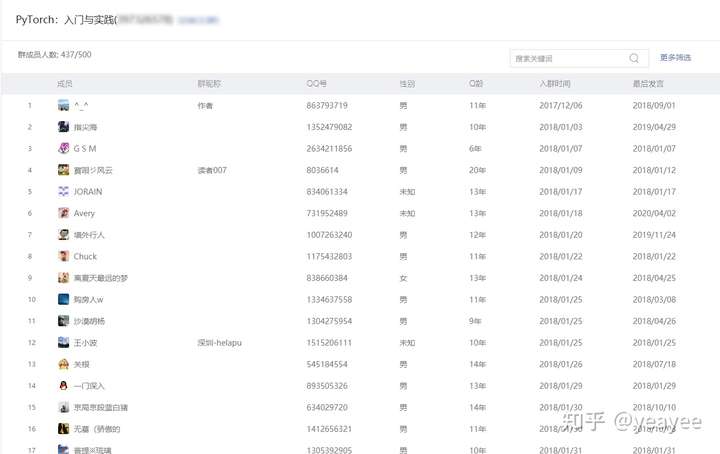
该方法适用于页面非JS动态加密文本的任一网站(大部分网站不会这么变态,现在更多网站都是基于前后端分离调用API实现内容展示)。很轻松获取到了某QQ群的成员信息,如下:

原始网页:
小结
不要一开始就想着多进程、分布式爬虫等等,做一个网站不容易,希望恪守爬虫职业道德,低速获取自己用的信息。