Python数据分析及可视化实例之爬虫源码(05)
1.背景介绍
(1)在注册了某网站之后,发现站内个人页面有个关于京杭大运河的征文。再加上之前,九寨沟地震第一时间机器人写了一篇通讯稿。于是我就在想,既然机器可以写通讯稿,那么是不是也可以用来写篇关于京杭大运河的征文?有个大概思路,那么就开撸吧。
(2)打开度娘,搜索:北京 运河 京杭,初步看看源代码结构。
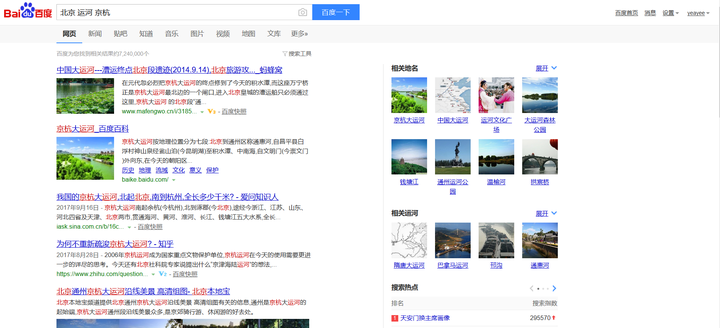
用Requests和Re(百度的搜索链接用正则要比BeautifulSoup方便一些),提取链接地址。

问题来了,提取出来的链接如下:
http://www.baidu.com/link?url=xrStztha3DcV7ycuutlYKna-IOpP4qUJ7x0F48oUfxvb9moDNuanGFVpA_r9q8y4k6bm6HxotwnLM6oRoVabtgMrKnk3b6ZH2VJNixURhLW用Requests进行get请求并不能获取目标页面响应,为毛?
因为link?url=?后面的密文需要用JS进行解密,而这个JS,Requests束手无策。是的,必须上PhantomJS进行JS渲染。
(2)用PhantomJS+Selinium对上免得加密链接进行访问(对前端JS非常熟悉的筒子,也可以逆向分析JS函数,在通过传参获取真实的URL,这招是传统的手工作坊)。用driver.page_source()获取真实地址对应的网页源码。
(3)这一次我并不是要对真实网页的某一网页标签进行提取,再者百度搜索结果的不同网站关于京杭大运河的文章格式都是不同的,没有办法提取。呵呵,此行目的是为了获取不同网站关于大运河新闻的文本或图片。
(4)对文本数据进行词频分析。预留作业:对采集到的图片用前面一节讲的生成照片墙。
2.分析结果(事先不知道京杭大运河是什么鬼)

- 始于1018年, 1026年, 1079年(1000年为错误匹配),经查证1018年就开挖了。
- 1293年、1779年、1958年、1968年京杭大运河发生了什么?
- 京杭大运河的报道主要来源:百科,腾讯,新浪。
- 大运河是中华民族的伟大工程,是南水北调伟大项目的组成部分。

- 大运河是民族的遗产,建成后将免费使用,不收过路费(瞎掰的)。
- 大运河建设关系到运输、旅游和农业灌溉。
- 大运河建设将拉动投资,有助于促进区域经济发展。

- 运河建设是世界性工程。
- 专家指出不管从历史、社会、人文、交通、地方、博物馆、商业等角度都是迫切的(瞎掰的)。

- 大运河要开凿,要以全新面貌重现辉煌。
- 大运河建成后将会加大保护力度,发展漕运,还得申遗。
- 招聘若干名漕运管理人员(瞎掰的,不招盐运)。
PS:如果你学会这招,补充一点历史知识,加上一张沿线美食、美景的照片墙,一篇高逼格的人机交互稿件就出来了。哪里需要征文都可以这样玩,自媒体也可以这样玩。
3.源码
(1)抓取百度初始化搜索页面源文件
# coding = utf-8
import requests
import re
headers = {
'Host': 'ss1.bdstatic.com',
'content-type': 'application/json',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36',
'Referer': 'https://www.baidu.com/s?wd=%E5%8C%97%E4%BA%AC%20%E8%BF%90%E6%B2%B3%20%E4%BA%AC%E6%9D%AD&pn=0&oq=%E5%8C%97%E4%BA%AC%20%E8%BF%90%E6%B2%B3%20%E4%BA%AC%E6%9D%AD',
'Connection': 'keep-alive'
}
base_url = 'https://www.baidu.com/'
s = requests.session()
s.get(base_url)
find_urls = []
for i in range(20):
print(i)
url = 'https://www.baidu.com/s?wd=%E5%8C%97%E4%BA%AC%20%E8%BF%90%E6%B2%B3%20%E4%BA%AC%E6%9D%AD&pn=' + str(
i * 10) # 关键词(北京 运河 京杭)
print(url)
content = s.get(url, headers=headers).text
find_urls.append(content)
find_urls = list(set(find_urls))
f = open('url.txt', 'a+',encoding='utf-8')
f.writelines(find_urls)
f.close()
(2)用正则提取搜索页面的初始URL(也可以用BS4)
# coding = utf-8
import re
f = open('url.txt',encoding='utf-8').read()
f2 = open('urlin.txt', 'a+',encoding='utf-8')
find_urls = re.findall('href="http://www.baidu.com/link(.+?)"', f )
find_urls = list(set(find_urls))
find_u = []
for url_i in find_urls:
in_url = 'http://www.baidu.com/link' + url_i + '\n'
f2.write(in_url)
f2.close()(3)用重器PhantomJS获取网页文本
# encoding: utf-8
# 导入可能用到的库
import requests, json, re, random, csv, time, os, sys, datetime
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
dcap = DesiredCapabilities.PHANTOMJS
dcap[ "phantomjs.page.settings.userAgent"] = "Mozilla / 4.0(Windows NT 10.0; Win64;x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome/51.0.2704.79 Safari/ 537.36Edge/14.14393"
# 请求头不一样,适应的窗口不一样!
driver = webdriver.PhantomJS(desired_capabilities=dcap)
driver.set_page_load_timeout(10)
driver.set_script_timeout(10)#这两种设置都进行才有效
find_urls = open('urlin.txt',encoding='utf-8').readlines()
# print(len(find_urls)) # 634个URL # 关键词(北京 运河 京杭)
i = 0
f = open('jh_text.txt', 'a+',encoding='utf-8')
for inurl in find_urls:
print(i,inurl)
i+=1
try:
driver.get(inurl)
content = driver.page_source
# print(content)
soup = BeautifulSoup(content, "lxml")
f.write(soup.get_text())
time.sleep(1)
except:
driver.execute_script('爬虫跳坑里,等会继续')(4)对50页百度搜索结果的文本(13.7M)剔除停用词,然后进行词频分析(pandas够了)。