Python数据分析及可视化实例之Request、BeautifulSoup
这一节看似好讲实则难以表述清楚,
讲不到的地方请别较真,也不要问爬虫哪家好?
我只说我知道的,怎么选择,兄弟们请随意。
1. WEB请求
第一段就难倒我了,非要讲述Web8种http请求方式,
无异于孔乙己知道茴字的N种写法(关键我也不会啊)。
先说说我学爬虫的过程,搬板凳,带瓜子,讲故事了:
每一个Python初学者大都绕不开爬虫的坑,
那年我玩CPC网赚,按键精灵、国产编程语言,大漠插件,靠谱助手,知道的举个手?
了解了Web前端的标签,网页像素级点击的方法,后台发送数据的技巧......
吾爱破解,小众软件社区跑多了觉得能破解、写软件看起来挺牛逼的,
偶然进了我乎,发现程序猿大牛真特么厉害,三条汪都还在,炒鸡偶像!
程序员们在撕逼PHP是宇内第一语言的时候,也顺便提到了人类未来Python,
人生苦短,我用Python,逼格当时就爆棚了,
没错,@ 廖雪峰,为人不识陈近南啊,照着他2.X教程撸3.X还是痛苦的,
之后他出了3.X,我就顺手爬了他的教程,做成的带标签的PDF,
现在还是吾爱破解的热帖(捂脸!)
如何爬技术博客专题,并将其作为带标签的PDF,请自行研究!
当然,那个时候@ 静觅丨崔庆才的系列博客也不能少。【操蛋,扯远了!】
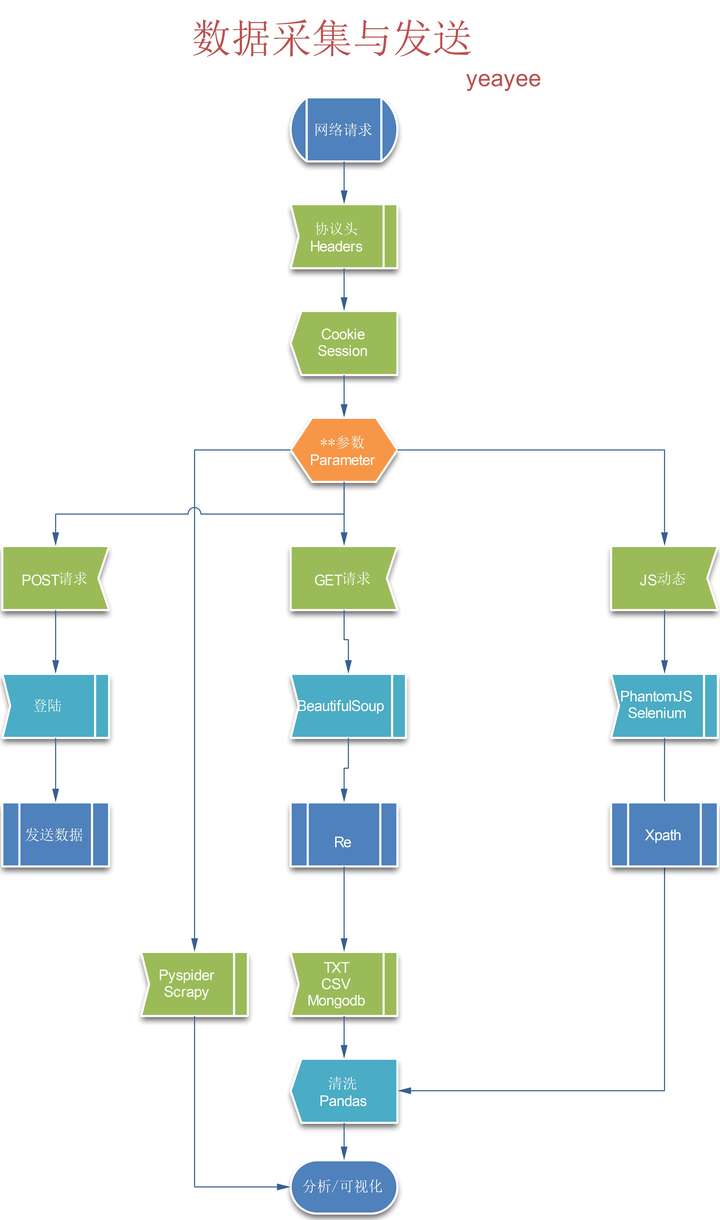
2.WEB请求流程及器具
第一步,IE准备HttpWatch(来自易语言启蒙教程,嘿嘿);火狐浏览器安装FireBug插件;通杀软件Fiddler,连费德勒都解决不了的,祭出神器Shark。
这个阶段,先了解一个网络请求是Get还是Post,请求协议头长什么样子,Post数据是什么格式、来源,响应都包含哪些,Html标签含义,JS的作用等等。挨个说起来就话长了。对了,你要抓APP,还的自备随身WIFI,设置Fiddler或Shark,无外乎获取canshu。
第二步,由于我坚定学习3.x,而Scrapy只支持2.7,所以我就从底层自己构建,包括后来的多线程,IP池,验证码,都一个个解决。所以我的建议是先不要用框架,等你熟悉了再用不迟。
网络请求不要纠结,用Requests:快速上手 - Requests 2.18.1 文档,别人的文档写的这么好了,我就不做搬运工,以后用实例慢慢解析。
第三步,GET请求成功(200)之后,相应就是Html源码,如何提取?Re正则肯定是万能的神器,但是结合BeautifulSoup你会觉得可以更简单,我个人的编程风格就是混搭风,英文、中文、pinyin混合使用,不拘泥于形式,以最短的路径实现功能,有点像大数据的梯度下降,越快越好。同样Beautiful Soup 4.2.0 文档也已经很完善,稍后用实例解析。
第四步,提取的数据保存,最开始自然是TXT格式,顺便熟悉以下TXT格式的读取,这个在任何时候都可能用到;然后是CSV,别以为import csv你就可以随便存了,里面还有不少坑,尤其是行头,嗯嗯,稍后实例解析。妹子高清图除外,图片是字节集,要用file保存。
题外话:我没有说POST是因为他除了用来登录以外,常常被用作各种论坛群发机,用作营销推广(留言板、站内信、顶帖),当然,账号被封也是家常便饭,所以本主不打算在我乎细说这个。呵呵,感兴趣的朋友可以看看这个:xchaoinfo/fuck-login
如果这个大牛的登陆源码你都系数看懂了,那你就可以自成一脉,专杀各种论坛、博客营销。如果想更深度的发扬这个体系,你还的搞定IP代理,验证码识别、自然语言NLP,路慢慢洗!
3.文末
我知道大家关注本专栏就是冲着实例来的,
别特么提底层框架?基础工程是我的专业,
其实,让我讲理论,水平欠缺,容易沟带,
不看广告,看疗效,下来爬一爬百度贴吧!